chesteR - reunião 06
Regressão Linear
Como visto no encontro anterior, o seguinte código instala os pacotes (caso você não tenha instalado) e os carrega para utilização:
pacotes <- c("ISLR", "olsrr", "car")
install_library <- lapply(pacotes,
FUN = function(x) {if (!require(x, character.only = TRUE)) {
install.packages(x, dependencies = TRUE)
library(x, character.only = TRUE)
}
}
)ISLRpacote que contém os dados que serão estudados;olsrrpacote para visualizar gráficos de premissa para regressão linear;carpacote para testar multicolinearidade e teste de homocedastecidade.
Informações sobre os dados de venda de assento de carro para bebê, que iremos utilizar para gerar o modelo linear:
??CarseatsRenomeando a base de dados:
dados_venda <- CarseatsA partir das variáveis fornecidas pela base, podemos gerar um modelo para prever o valor das cadeiras de bebê, de acordo com os outros fatores existentes. Com isso será possível notar quais variáveis influenciam nas vendas de forma geral.
Criando o modelo de regressão linear entre as variáveis de venda de cadeirinha de bebê, através da função lm(). Obs.: lm = linear model:
fit1 <- lm(formula = Sales ~ ., data = dados_venda); summary(fit1)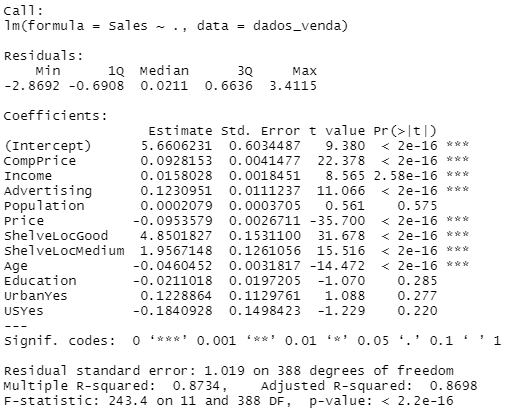
Note que para construirmos o modelo, foram utilizados 2 argumentos: formula e data. Na fórmula do modelo nós precisamos colocar antes do ~ a variável dependente, e após o ~ colocamos as variáveis independentes. O . representa uma abreviação de que utilizaremos todas as variáveis presentes na base, ou seja, o . equivale a escrever o nome de cada variável e colocar um sinal de + entre elas. Além disso, é importante notar que estamos utilizando ; que representa uma quebra de linha, logo, estamos rodando 2 linhas de código em uma linha só. A segunda linha de código summary(fit1) nos apresenta o resumo dos resultados do modelo, os quais estão representados logo abaixo do código.
Sabendo disso, a partir do resultado do modelo, nós iremos retirar as variáveis que não foram significativas. E para fazer isso basta subtraí-las na fórmula:
fit1 <- update(fit1, ~ . - Population - Education - Urban - US); summary(fit1)
E com isso, criaremos 2 variáveis de interação que podem ser úteis. E para criar interação entre variáveis é necessário utilizar os dois pontos entre elas:
fit1 <- update(fit1, ~ . + Income:Advertising + Age:Price); summary(fit1)
No entanto, a interação entre preço e idade não foi significativa, por isso iremos retirar essa variável do mesmo modo que subtraímos as demais:
fit1 <- update(fit1, ~ . - Age:Price); summary(fit1)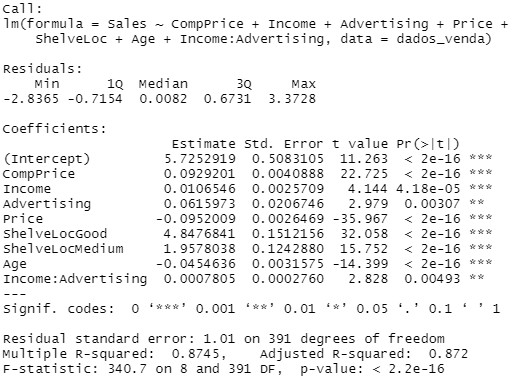
A título de curiosidade a fórmula escrita por extenso ao chegar no final dos ajustes (não é necessário escrevê-la assim), foi equivalente a:
lm(formula = Sales ~ CompPrice + Income + Advertising + Price +
ShelveLoc + Age + Income:Advertising, data = dados_venda)Premissas de uma regressão linear (LINE):
L inearity
I ndependence
N ormality
E qual variance
As premissas acima podem ser analisadas graficamente através dos gráficos do modelo:
par(mfrow = c(2,2)); # definindo o layout da página com 2 colunas e 2 linhas
# para comportar todos os 4 gráficos do plot(fit1)
plot(fit1)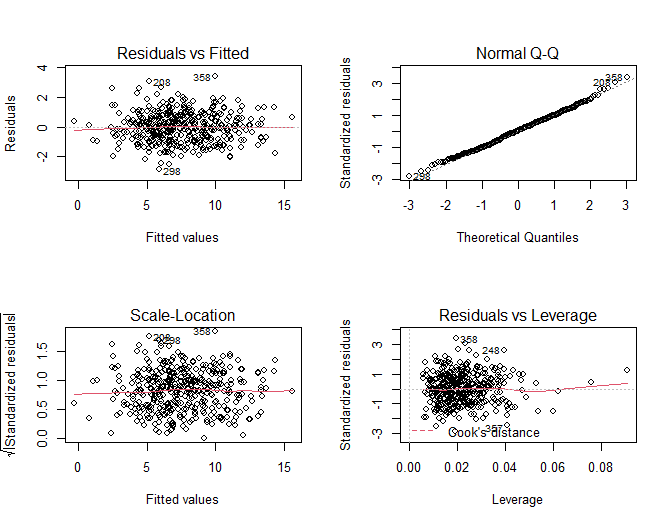
ou utilizando as funções do pacote olsrr as quais geram alguns dos mesmos gráficos vistos acima mas com layout mais elaborado:
ols_plot_resid_fit(fit1); # gráfico de resíduosols_plot_resid_qq(fit1); # gráfico de quantilesols_plot_resid_hist(fit1) # histograma
Aqui, por simplicidade, seguiremos utilizando apenas os gráficos gerados pela função plot() para fazermos as interpretações.
Interpretação dos gráficos:
Residuals x Fitted values: demonstra se os resíduos têm padrões não lineares, nesse caso a linha vermelha indica um padrão linear.
Normal Q-Q: demonstra se os resíduos têm distribuição normal, nesse caso os resíduos seguem a distribuição normal (linha pontilhada).
Scale Location: demonstra se os resíduos são distribuídos ao redor dos preditores, esse gráfico representa a homocedastecidade (resíduos igualmente distribuídos) de forma clara.
Residuals x Leverage: pontos fora dessa distância, alcançando o extremo superior direito ou inferior direito com linhas pontilhadas vermelhas nessas posições indicam não linearidade ou a presença de outliers. Nesse caso isso não acontece.
Além da análise gráfica, a qual pode não ser conclusiva, é possível testar numericamente as premissas da regressão linear. Com isso temos o teste de normalidade, de colinearidade e de heterocedasticidade.
Testando normalidade:
ols_test_normality(fit1)| Test | Statistic | p-value |
|---|---|---|
| Shapiro-Wilk | 0.9969 | 0.6563 |
| Kolmogorov-Smirnov | 0.0316 | 0.8193 |
| Cramer-von Mises | 27.3033 | 0.0000 |
| Anderson-Darling | 0.2778 | 0.6502 |
O teste de Shapiro-Wilk testa a normalidade. Logo, se o valor de p for igual ou menor que 0.05, a hipótese de normalidade será rejeitada. Os demais testes também são semelhantes, com interpretações equivalentes à de que a distribuição desses dados é normal.
Testando multicolinearidade: VIF (Variation Inflation Factor) > 10 representa a colinearidade entre variáveis, que nem sempre é problemática, depende da situação na vida real. Por isso é necessário agir com cuidado quando se pretende remover variáveis que apresentam esse comportamento.
vif(fit1)| Variables | GVIF | Df | GVIF^(1/(2*Df)) |
|---|---|---|---|
| CompPrice | 1.536280 | 1 | 1.239468 |
| Income | 2.022959 | 1 | 1.422308 |
| Advertising | 7.387554 | 1 | 2.718006 |
| Price | 1.534807 | 1 | 1.238873 |
| ShelveLoc | 1.015941 | 1 | 1.003962 |
| Age | 1.022483 | 1 | 1.011179 |
| Income:Advertising | 8.695282 | 1 | 2.948776 |
Obs.: a multicolinearidade aumenta a variância dos coeficientes estimados, e dificulta a interpretação do modelo, por esse motivo variáveis desse tipo costumam ser removidas do modelo. Nesse caso nenhuma variável apresentou VIF > 10.
Testando homocedastecidade Breusch-Pagan: Modelos lineares requerem homocedasticidade, isto é, os resíduos devem estar bem distribuídos.
ncvTest(fit1)Non-constant Variance Score Test Variance formula: ~ fitted.values Chisquare = 0.1259146, Df = 1, p = 0.72271
Se o valor de p for igual ou menor que 0.05, a hipótese de homocedastecidade será rejeitada. Logo, nesse caso, é possível afirmar estatisticamente que os resíduos estão bem distribuídos e que o modelo cumpre as premissas estatísticas.